
Parsing Hive Create table query using Apache Hive library
Contents
Apache Hive
Apache Hive is an open source data warehousing solution build on top of Hadoop. It supports SQL-like query language called as HiveQL. The query execution happens using Apache Hadoop MapReduce or Apache Tez frameworks. The Hive project details are available in GitHub. So we can use its library to parse the HiveQL. In this tutorial, we will write a Java program to parse the Hive Create table query.
Abstract Syntax Tree (AST)
Before executing the Query,Hive parser generate a syntactic structure of the sql. It is called as parse tree. The output of the parser is usually an Abstract Syntax Tree (AST). Hive uses Antlr to generate the abstract syntax tree (AST) for the query.
For the simple create table query, Hive parser generates the AST tree like below. Basically it split the sql into tokens such as TOK_CREATETABLE, TOK_TABNAME and so on. Then it build the AST tree based on those tokens.
create table <table_name>
(<column_1> <data_type>,
<column_2> <data_type>)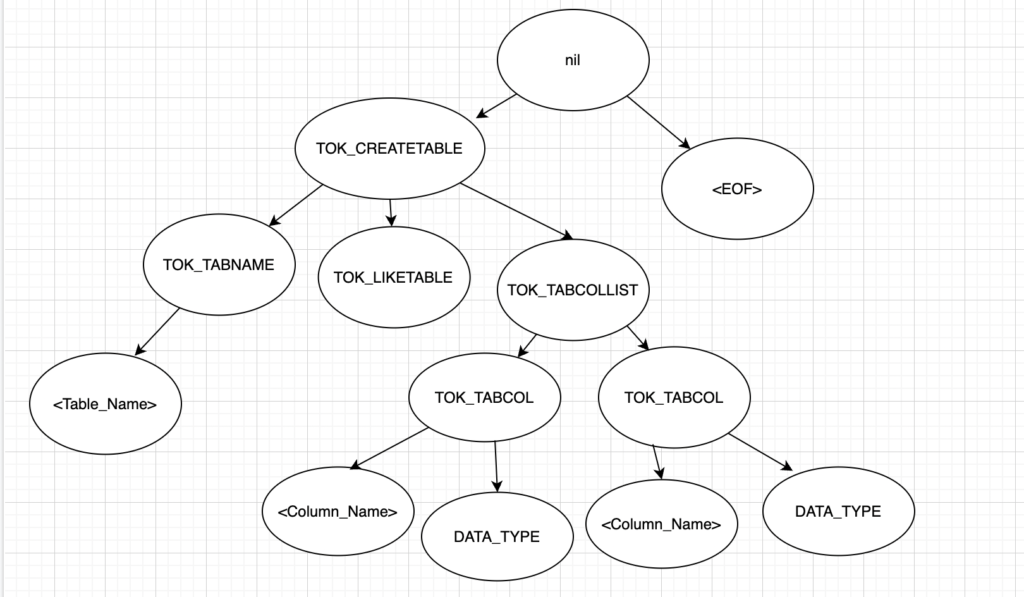
Java program to parse the Hive Create table query
Consider that, we have a Hive create table query. From that query, we want to get the table name, column name and data type of the columns. It is possible with the help of Apache Hive library. Let’s start writing the java program to parse the Create table statement.
Step 1: Set the Hive dependency in pom.xml
To add the Hive libraries in the program, we are creating the Maven project in IntelliJ IDEA. Then we need to add the Hive dependency in the pom.xml file. Here we are using Hive version 2.3.7. Based on the requirement, we can change the Hive version in this file. The maven tool download/include the relevant jar files in our project.
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.3.7</version>
</dependency>Step 2 : Assign the input query to the variable
In the main function, we are assigning the Hive create table query to the variable. We will parse this query in the following steps.
String input ="CREATE TABLE Test_Cust (Cust_id int,Name string)";Step 3 : Create a ParseDriver Object
The ParseDriver class has the parse method to process the Hive QL. Let’s create a ParseDriver object as below
ParseDriver pd = new ParseDriver();Step 4 : Parse the input Sql
Using the ParserDriver object, we can call the parse method. Let’s call this method with the input of Create table Sql, It will return the Abstract Syntax Tree (AST). In Hive library, it is mapped to a class ASTNode.
ASTNode tree = pd.parse(input);Step 5 : Print the Parse tree
In this step, we are just printing the input and ASTNode. The node class has a function dump which is returning the below parse tree.
System.out.println("Input Hive Sql : " + input);
//Printing AST tree
System.out.println(tree.dump());Input Hive Sql : CREATE TABLE Test_Cust (Cust_id int,Name string)
nil
TOK_CREATETABLE
TOK_TABNAME
Test_Cust
TOK_LIKETABLE
TOK_TABCOLLIST
TOK_TABCOL
Cust_id
TOK_INT
TOK_TABCOL
Name
TOK_STRING
<EOF>Step 6 : Traverse the AST node
As we shown in the earlier tree diagram, set of ASTNodes linked together and created a AST tree. We need to traverse the tree to get the required details.
The parent node of this tree is nil. It has two children such as TOK_CREATETABLE & <EOF>. To get the table name, column name and data type, we need to parse the child of node TOK_CREATETABLE. For that we created a separate function as traverseASTNode.
if(tree.getChildren() != null){
for(Node eachNode : tree.getChildren()){
ASTNode astNode = (ASTNode) eachNode;
//Calling the traverseASTNode function to loop through the child nodes
if(astNode.getChildren() != null)
traverseASTNode(astNode.getChildren());
}
}Step 7 : Loop through each Child node
We passed the child nodes of TOK_CREATETABLE to function traverseASTNode. To iterate each node, we write a for loop. Then we are checking the node type of the parent node. Based on the node type such as TOK_TABNAME & TOK_TABCOL, we are getting the table name and column name from the current node.
The HiveParser class maintaining each node type values. For this example, we used only HiveParser.TOK_TABNAME & HiveParser.TOK_TABCOL in the switch case statement.
Also to get the data type of the column, we used only HiveParser.TOK_INT & HiveParser.TOK_STRING. These values are mapped for int and string data types. For other data types, we need to include respective value here.
Please note that if any of the node has a child node, we are calling the function traverseASTNode again at the end. It is a recursive function in the program.
public static void traverseASTNode(List<Node> astNodeList){
for(Node eachNode : astNodeList){
ASTNode astNode = (ASTNode) eachNode;
//Get the node type of parent AST node
int parentNodeType = astNode.getParent().getType();
String tableName,columnText;
int NodeType;
//Validate the node type to get the SQL details
switch (parentNodeType){
case HiveParser.TOK_TABNAME:
tableName = astNode.getToken().getText();
System.out.println("Table Name : " + tableName);
break;
case HiveParser.TOK_TABCOL:
//Get the current AST node type
NodeType = astNode.getType();
//Get the Token text of the AST node for the column Name
columnText = astNode.getText();
// Checking the parentNodeType which corresponds to DataType
if(NodeType == HiveParser.TOK_INT || NodeType == HiveParser.TOK_STRING)
System.out.println("Data Type : " + dataTypeMap.get(NodeType));
else{
System.out.println("Column Name : " + columnText);
}
break;
}
//Recursive function to traverse the child node of current AST node
if(astNode.getChildren() != null)
traverseASTNode(astNode.getChildren());
}
}Step 8: Create a HashMap variable for data type mapping
Also we created a Hashmap variable dataTypeMap which holds the key value pair of Hive parser value and corresponding data type. To get the data type of the column, we used this variable in the previous function traverseASTNode => dataTypeMap.get(NodeType)
private static Map<Integer, String> dataTypeMap;
static
{
dataTypeMap = new HashMap<>();
dataTypeMap.put(HiveParser.TOK_INT, "int");
dataTypeMap.put(HiveParser.TOK_STRING, "string");
dataTypeMap.put(HiveParser.TOK_DATE, "date");
}Step 9: Complete program code and execution
We combined all the above steps and presenting the complete program to parse the Hive Create table query.
import org.apache.hadoop.hive.ql.lib.Node;
import org.apache.hadoop.hive.ql.parse.ASTNode;
import org.apache.hadoop.hive.ql.parse.HiveParser;
import org.apache.hadoop.hive.ql.parse.ParseDriver;
import org.apache.hadoop.hive.ql.parse.ParseException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class TestParseHiveSql {
// Declaring the static map for Hive Data Type
private static Map<Integer, String> dataTypeMap;
static
{
dataTypeMap = new HashMap<>();
dataTypeMap.put(HiveParser.TOK_INT, "int");
dataTypeMap.put(HiveParser.TOK_STRING, "string");
dataTypeMap.put(HiveParser.TOK_DATE, "date");
}
public static void main(String[] args) {
// Input Create Table Statement
String input ="CREATE TABLE Test_Cust (Cust_id int,Name string)";
//Create a ParseDriver object
ParseDriver pd = new ParseDriver();
try {
//Get Abstract Syntax Tree(AST) by parsing the input Hive Sql
ASTNode tree = pd.parse(input);
System.out.println("Input Hive Sql : " + input);
//Printing AST tree
System.out.println(tree.dump());
// Start traverse the AST tree if it has children AST node
if(tree.getChildren() != null){
for(Node eachNode : tree.getChildren()){
ASTNode astNode = (ASTNode) eachNode;
//Calling the traverseEachNode function to loop through the child nodes
if(astNode.getChildren() != null)
traverseASTNode(astNode.getChildren());
}
}
} catch (ParseException e) {
throw new RuntimeException(e);
}
}
public static void traverseASTNode(List<Node> astNodeList){
for(Node eachNode : astNodeList){
ASTNode astNode = (ASTNode) eachNode;
//Get the node type of parent AST node
int parentNodeType = astNode.getParent().getType();
String tableName,columnText;
int NodeType;
//Validate the node type to get the SQL details
switch (parentNodeType){
case HiveParser.TOK_TABNAME:
tableName = astNode.getToken().getText();
System.out.println("Table Name : " + tableName);
break;
case HiveParser.TOK_TABCOL:
//Get the current AST node type
NodeType = astNode.getType();
//Get the Token text of the AST node for the column Name
columnText = astNode.getText();
// Checking the parentNodeType which corresponds to DataType
if(NodeType == HiveParser.TOK_INT || NodeType == HiveParser.TOK_STRING)
System.out.println("Data Type : " + dataTypeMap.get(NodeType));
else{
System.out.println("Column Name : " + columnText);
}
break;
}
//Recursive function to traverse the child node of current AST node
if(astNode.getChildren() != null)
traverseASTNode(astNode.getChildren());
}
}
}
Output
Input Hive Sql : CREATE TABLE Test_Cust (Cust_id int,Name string)
nil
TOK_CREATETABLE
TOK_TABNAME
Test_Cust
TOK_LIKETABLE
TOK_TABCOLLIST
TOK_TABCOL
Cust_id
TOK_INT
TOK_TABCOL
Name
TOK_STRING
<EOF>
Table Name : Test_Cust
Column Name : Cust_id
Data Type : int
Column Name : Name
Data Type : stringAfter executing the program, we can see that the table name, column name and data type are fetched from the Hive CREATE TABLE query. Those details are printed in the console.
Recommended Articles