
How to copy Hadoop data from On-Premise to Google Cloud Storage(GCS)?
Contents
Cloud Storage Connector
Cloud Storage Connector is an open source Java library developed by Google. It allows us to copy the data from On-Premise to Google Cloud Storage.
With the help of this connector, We can access the cloud storage data from the On-Premise machine. Also, Apache Hadoop and Spark jobs can access the files in Cloud Storage using this connector.
Configure the connector in On-Premise Hadoop cluster
To access the Google Cloud Storage from On-Premise, we need to configure the Cloud Storage Connector in our Hadoop Cluster. The following steps needs to be done.
- Download the Cloud Storage Connector as per our Hadoop version. The connector can be found in Google’s official site.
- Copy this connector jar file to $HADOOP_COMMON_LIB_JARS_DIR directory (eg: hadoop/3.3.3/libexec/share/hadoop/common).
- Create service account and download the key file in json format for the GCP project
- Copy the service account key file to every node in on-prem hadoop cluster.(eg: hadoop/3.3.3/libexec/etc/hadoop)
- Add below properties in the core-site.xml file in the Hadoop cluster. (eg. hadoop/3.3.3/libexec/etc/hadoop/core-site.xml).
- We need to replace /path/to/keyfile with the actual service account key file path in the property google.cloud.auth.service.account.json.keyfile. For more details, please refer Github
<property>
<name>fs.AbstractFileSystem.gs.impl</name>
<value>com.google.cloud.hadoop.fs.gcs.GoogleHadoopFS</value>
<description>The AbstractFileSystem for 'gs:' URIs.</description>
</property>
<property>
<name>fs.gs.project.id</name>
<value></value>
<description>
Optional. Google Cloud Project ID with access to GCS buckets.
Required only for list buckets and create bucket operations.
</description>
</property>
<property>
<name>google.cloud.auth.type</name>
<value>SERVICE_ACCOUNT_JSON_KEYFILE</value>
<description>
Authentication type to use for GCS access.
</description>
</property>
<property>
<name>google.cloud.auth.service.account.json.keyfile</name>
<value>/path/to/keyfile</value>
<description>
The JSON keyfile of the service account used for GCS
access when google.cloud.auth.type is SERVICE_ACCOUNT_JSON_KEYFILE.
</description>
</property>Command to copy the HDFS file from On-Premise to GCS bucket
Now we can copy the HDFS file to GCS bucket. We have a file Online_Retail_Dataset.csv in on-prem Hadoop cluster as below
Source location
hdfs dfs -ls /rc_prod
Found 1 items
-rw-r--r-- 1 rc_user_1 supergroup 838 2022-07-22 16:22 /rc_prod/Online_Retail_Dataset.csvDestination location
We want to copy this file to Google cloud storage bucket rc_projects. Currently it doesn’t have any data.
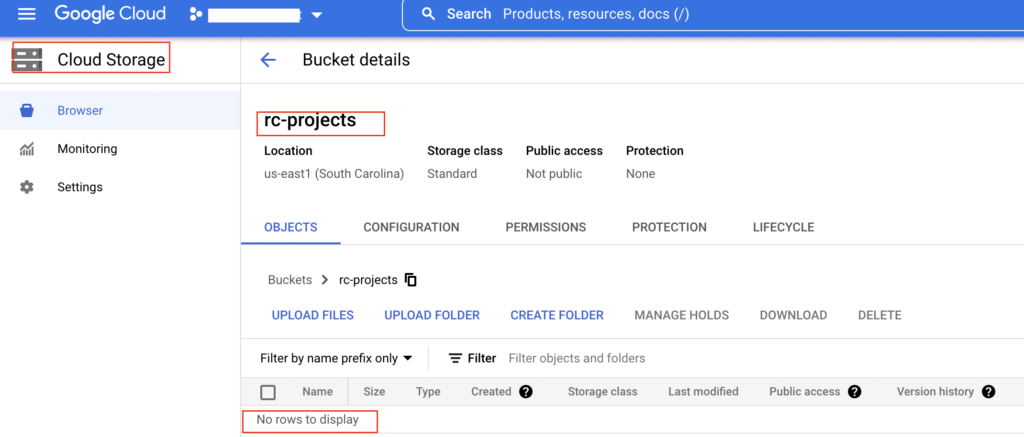
Let’s run the hdfs copy command to copy the HDFS file Online_Retail_Dataset.csv to GCS bucket rc_projects
hdfs dfs -cp /rc_prod/Online_Retail_Dataset.csv gs://rc-projectsThe command is executed successfully. We can check the file in GCS by running the hdfs dfs -ls command as below.
hdfs dfs -ls gs://rc-projects
-rwx------ 3 rc_user_1 rc_user_1 838 2022-07-22 16:38 gs://rc-projects/Online_Retail_Dataset.csvLet’s verify the same in GCS using Google cloud console. As we shown below, the file Online_Retail_Dataset.csv is present in the GCS bucket.
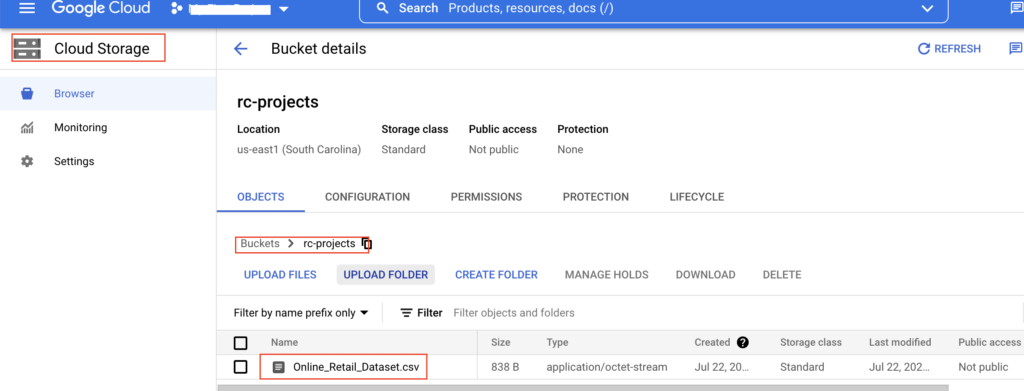
If the HDFS file is large, we can copy it using hadoop distcp command as below. It will speed up the copy process.
hadoop distcp /rc_prod/Online_Retail_Dataset.csv gs://rc-projectsFinally we have migrated on-prem Hadoop data to Google Cloud Storage successfully.
Recommended Articles
- How to export data from BigQuery table to a file in Cloud Storage?
- Create a Hive External table on Google Cloud Storage(GCS)
- How to load JSON data from Cloud storage to BigQuery?
References from GCP official documentation
Your Suggestions