
How to write a Spark dataframe to Hive table in Pyspark?
Contents
Apache spark to write a Hive Table
Apache Spark provides an option to read from Hive table as well as write into Hive table. In this tutorial, we are going to write a Spark dataframe into a Hive table. Since Spark has an in-memory computation, it can process and write a huge number of records in much faster way. Lets write a Pyspark program to perform the below steps.
- Read the data from the csv file and load it into dataframe using Spark
- Write a Spark dataframe into a Hive table.

Create a Spark dataframe from the source data (csv file)
We have a sample data in a csv file which contains seller details of E-commerce website. Using the Spark Dataframe Reader API, we can read the csv file and load the data into dataframe. The csv file seller_details.csv has the below data and it resides in the following path /x/home/user_alex. We are going to load this data into Spark dataframe.
SELLER_ID,SELLER_NAME,CATEGORY,ONBOARDING_DT
4849,Jabra,Audio and Video,2021-12-20
5763,Powells,Books,2021-10-15
4353,The Pink Stuff,Home Cleaning,2022-01-10
3848,Garden Safe,Gardening,2022-01-15Lets create a spark session variable with the name of “spark”. This variable is used to access the read method of Dataframe Reader API
appname = "TEST_DATAFRAME_TO_HIVE_TABLE"
spark = SparkSession.builder.appName(appname).enableHiveSupport().getOrCreate()Next we need to create the schema of the dataframe with the data type. Based on the source data which is in the csv file, we are creating the below schema.
sellerSchemaStruct = StructType([
StructField("SELLER_ID", IntegerType()),
StructField("SELLER_NAME", StringType()),
StructField("CATEGORY", StringType()),
StructField("ONBOARDING_DT", DateType())
])Now we need to call the read method of Dataframe Reader API using the spark session variable.Lets write a code to load the csv data into Dataframe.
- path of the source data – /x/home/user_alex/seller_details.csv
- mode for dealing with corrupt records – FAILFAST (throws an exception when it meets corrupted records)
- schema of the dataframe – sellerSchemaStruct (schema variable is created in previous step)
- input option – Since our csv file has header record, we set it as true.
- data source format – specified the input data source format as csv.
sellerDetailsCsvDF = spark.read \
.format("csv") \
.option("header", "true") \
.schema(sellerSchemaStruct) \
.option("mode", "FAILFAST") \
.load("/x/home/user_alex/seller_details.csv")The dataframe sellerDetailsCsvDF will be created with the above statement.
Write a Spark dataframe to a Hive table
Similar to Dataframe Reader API, Spark has a Dataframe Writer API to handle the write operation. It has a write method to perform those operation. Using any of our dataframe variable, we can access the write method of the API.
We have two different ways to write the spark dataframe into Hive table.
Method 1 : write method of Dataframe Writer API
Lets specify the target table format and mode of the write operation.
- Output data format – We mentioned the output data format as ORC. The default format is parquet.
- mode – It specify the behaviour when the table is already exist. We mentioned as overwrite to overwrite the existing data.
sellerDetailsCsvDF.write
.format("orc") \
.mode("overwrite") \
.saveAsTable("Sales_Db.seller_details")Method 2 : create a temporary view
The createOrReplaceTempView method is used to create a temporary view from the dataframe. We created the view with the name of temp_table. This can be used as Hive table. The lifetime of this temporary table is tied to the SparkSession that was used to create this DataFrame.
Next we can execute the “create table as” statement to create the Hive table using the view name. Here the target table is seller_details and the database name is Sales_Db.
sellerDetailsCsvDF.createOrReplaceTempView("temp_table")
spark.sql("create table Sales_Db.seller_details as select * from temp_table");Complete code to create a dataframe and write it into a Hive Table
The Pyspark program is saved with the name as write_df_to_hive.py. The program execution is starts from main method (if name == “main“:). In this program, we are using the Dataframe write function to save the dataframe as Hive table. The another option to write a hive table is that creating a temporary view which is commented in the program.
from pyspark.sql import SparkSession
from pyspark.sql.types import *
def LoadSellersToHiveTable():
# create schema with data type for dataframe
sellerSchemaStruct = StructType([
StructField("SELLER_ID", IntegerType()),
StructField("SELLER_NAME", StringType()),
StructField("CATEGORY", StringType()),
StructField("ONBOARDING_DT", DateType())
])
# load the .csv file data to spark dataframe
sellerDetailsCsvDF = spark.read \
.format("csv") \
.option("header", "true") \
.schema(sellerSchemaStruct) \
.option("mode", "FAILFAST") \
.load("/x/home/user_alex/seller_details.csv)
# print a dataframe to the console
sellerDetailsCsvDF.show()
####Method 1 - write method ######
# save dataframe to a Hive table
sellerDetailsCsvDF.write \
.format("orc") \
.mode("overwrite") \
.saveAsTable("Sales_Db.seller_details")
######Method 2 - createOrReplaceTempView method#####
# register dataframe to a temporary view
#sellerDetailsCsvDF.createOrReplaceTempView("temp_table")
# create a table seller_details by selecting the contents of temp_table
#spark.sql("create table Sales_Db.seller_details as select * from temp_table");
#Main program starts here
if __name__ == "__main__":
appname = "TEST_DATAFRAME_TO_HIVE_TABLE"
spark = SparkSession.builder.appName(appname).enableHiveSupport().getOrCreate()
LoadSellersToHiveTable()
spark.stop()Shell script to run the Pyspark program => test_script.sh
In this shell script, we are setting the Spark environment variable and running the spark-submit command to execute our Pyspark program write_df_to_hive.py.
#!/bin/bash
echo "Info: Setting global variables"
export SPARK_MAJOR_VERSION=2
export SPARK_HOME=/usr/hdp/2.6.5.0-292/spark2
export PATH=$SPARK_HOME/bin:$PATH
spark-submit /x/home/user_alex/test/write_df_to_hive.pyExecute the shell script to run the Pyspark program
Finally we can run the shell script test_script.sh. It will execute Pyspark program to write the dataframe to Hive table.
sh test_script.shOutput
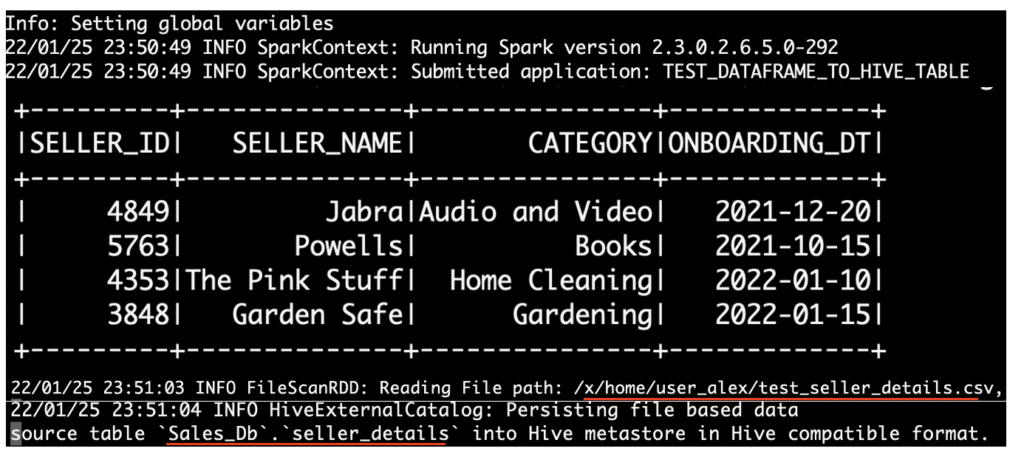
Lets check the Hive table seller_details in database Sales_Db. The Spark dataframe is saved as Hive table as below. The data is looks good. Also we checked the data type of the columns and format of the table using show create table statement. Appropriate data type is mapped for each columns as below. The table is created with the format of ORC as we given in the Pyspark program.
hive> select * from Sales_Db.seller_details;
OK
seller_id seller_name category onboarding_dt
4849 Jabra Audio and Video 2021-12-20
5763 Powells Books 2021-10-15
4353 The Pink Stuff Home Cleaning 2022-01-10
3848 Garden Safe Gardening 2022-01-15
Time taken: 0.065 seconds, Fetched: 4 row(s)
hive> show create table Sales_Db.seller_details;
OK
createtab_stmt
CREATE TABLE `seller_details`(
`seller_id` int,
`seller_name` string,
`category` string,
`onboarding_dt` date)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
WITH SERDEPROPERTIES (
'path'='hdfs://revisit_class/apps/hive/warehouse/Sales_Db.db/seller_details')
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
LOCATION
'hdfs://revisit_class/apps/hive/warehouse/Sales_Db.db/seller_details'Recommended Articles
- Read from Hive table using Pyspark
- How to send Spark dataframe values as HTML table to Email?
- How to read BigQuery table using PySpark?
Your Suggestions