
How to read BigQuery table using PySpark?
Contents
Spark BigQuery Connector
The Google Cloud team has created the set of connectors to access the data in GCP. To access BigQuery using Spark, they have released the Apache Spark SQL connector for Google BigQuery. Under the project Google Cloud Dataproc in GitHub, we can check more information about this connector. In this tutorial, we will use that connector and write a PySpark program to read the BigQuery table.
Prerequisites to read BigQuery table using PySpark
- Spark BigQuery connector jar file – We can download this connector file either from GitHub or GCS library gs://spark-lib/bigquery/. The connector files are available for different Spark/Scala versions. We need to check Spark Compatibility Matrix in GitHub and download the respective connector jar based on our Spark version. Using gsutil ls command, we can list down all the connector files. Then we can copy it to our machine using gsutil cp command.
$ gsutil ls gs://spark-lib/bigquery/
gs://spark-lib/bigquery/spark-bigquery-latest.jar
gs://spark-lib/bigquery/spark-bigquery-latest_2.11.jar
gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar$ gsutil cp gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar .- Service account and its key – To access the BigQuery programmatically, we need a service account and its key which is used to verify the client identity in BigQuery.
- Permissions – To read a BigQuery table using Service account, we need the following roles for our service account
- BigQuery Data Viewer
- BigQuery Job User
- BigQuery Read Session User
PySpark program to read BigQuery table
Step 1 : Import modules
In order to create Spark session, we need to import the SparkSession from pyspark.sql module
from pyspark.sql import SparkSessionStep 2: Create a Spark session
In the below statement, we are creating the Spark session using SparkSession.builder(). Since we are going to run this program in local machine, we set the master as local.
If we want to run this program in GCP DataProc cluster, we can set the master as yarn. Also the name of application is set it as “spark-read-from-bigquery”.
spark = SparkSession.builder.master('local')\
.appName('spark-read-from-bigquery')\
.getOrCreate()Step 3 : Read data from BigQuery table
Using Spark Dataframe Reader API, we can read the data from different sources. Here we are reading the data from BigQuery by setting the spark.read.format as bigquery. Also BigQuery related options are set in the spark.read command. Please refer GitHub for more such options.
- credentialsFile – To authenticate BigQuery using Service account, the path of the service account key file is set in this option.
- table – The option table is used to set the BigQuery table name from which we are going to read the data. We have given the table in the format <project_id>.<dataset_name>.<table_name>.
df = spark.read.format("bigquery") \
.option("credentialsFile","/Users/rc_user/pyspark_bq_tutorial/my-rcs-project-833123-ef45632b1b12.json") \
.option("table","my-rcs-project-833123.rc_fin_test_tables.compliance_base")\
.load()Step 4: Print the dataframe
In this step, we are just printing the BigQuery data and its schema from Spark dataframe.
df.limit(2).show()
df.printSchema()Local setup configuration and BigQuery table
Before running the program, we just want to show the version details of Spark,BigQuery Connector and Java in our local machine.
Spark version: 3.2.1
BigQuery connector version: 2.12
Java version: 1.8Source BigQuery table : rc_fin_test_tables.compliance_base
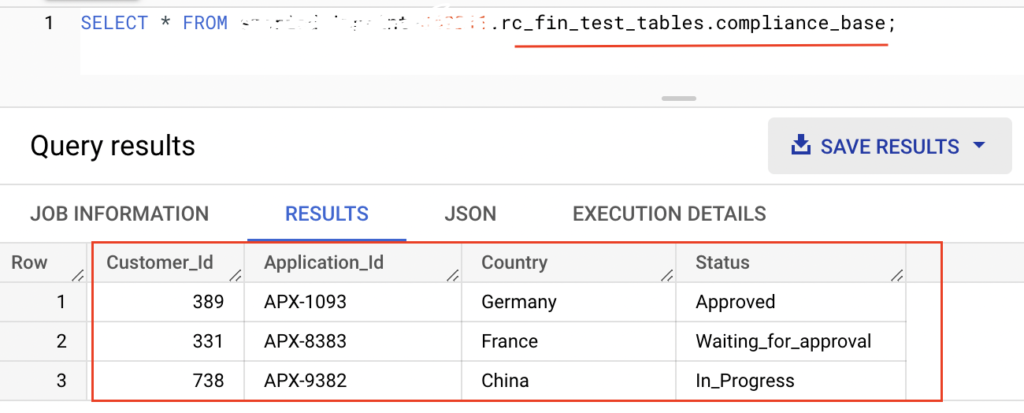
Command to submit PySpark job in local
Now we can run the PySpark program using spark-submit command as below. In the command, we have included the Spark BigQuery connector jar file as well.
spark-submit\
--jars=/Users/rc_user/pyspark_bq_tutorial/spark-bigquery-latest_2.12.jar\
test_py_bq.pyOutput
As shown below, the Pyspark program has read the data from BigQuery table and printed the records in the logs.

Command to submit PySpark job in DataProc Cluster
We can submit this PySpark program to GCP DataProc Cluster using gcloud command. To do so, Please follow the below steps and submit the gcloud command
- Create DataProc Cluster in GCP
- Upload the Service account key file in GCP VM instance which is created during the cluster creation.
- Get the service account key file path in VM instance and Update it in PySpark Program
- Set the master as yarn in the program => SparkSession.builder.master(‘yarn’)
- Provide the DataProc Cluster name and region name in the gcloud command as below
gcloud dataproc jobs submit pyspark test_py_bq.py \
--cluster=rc-data-cluster \
--region=us-central1 \
--jars=gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jarOnce the spark job is completed successfully, we can delete the Dataproc cluster to reduce the cost in GCP.
Complete PySpark program for your reference => test_py_bq.py
from pyspark.sql import SparkSession
#create spark session
spark = SparkSession.builder.master('local')\
.appName('spark-read-from-bigquery')\
.getOrCreate()
# Read BigQuery table and load it into Spark dataframe
df = spark.read.format("bigquery") \
.option("credentialsFile","/Users/rc_user/pyspark_bq_tutorial/my-rcs-project-833123-ef45632b1b12.json") \
.option("table","my-rcs-project-833123.rc_fin_test_tables.compliance_base")\
.load()
# print the dataframe with 2 records
df.limit(2).show()
# print schema of the dataframe
df.printSchema()Recommended Articles
- How to run a BigQuery SQL using Python?
- How to access a Hive table using Pyspark?
- Create Dataproc Cluster, submit Hive job and delete cluster using gcloud command
References from GCP official documentation
Your Suggestions