
How to submit a BigQuery job using Google Cloud Dataflow/Apache Beam?
Contents
Dataflow in GCP
Dataflow in GCP offers simplified streaming and batch data processing service based on Apache Beam. It allows us to build and execute data pipeline (Extract/Transform/Load).
The data pipeline can be written using Apache Beam, Dataflow template or Dataflow SQL. To execute the data pipeline, it provides on demand resources. Also it is providing the option to monitor the data pipeline execution.
Apache Beam
Apache Beam is a unified model for defining both batch and streaming parallel data processing pipelines. Apache beam SDK is available for both Java and Python.
It allows developers to write the data pipeline either Java or Python programming language. It supports runners (distributed processing back-ends) including direct runner,Apache Flink, Apache Samza, Apache Spark and Google Cloud Dataflow.
In this tutorial, we will write the Beam pipeline using Python program. Also the runner of the pipeline is Cloud dataflow.
Prerequisites to submit a BigQuery job in Dataflow
- Apache Beam SDK for python – Install SDK using pip command as below
pip install --upgrade 'apache-beam[gcp]'- BigQuery permission – To write the data into BigQuery, the service account should have a role BigQuery Data Editor
- Dataflow permission
- Dataflow API – To access the Dataflow service, Dataflow API should be enabled in GCP.
- Roles – Our service account should have the following role access to run the workers in dataflow Cloud Dataflow Service Agent & Dataflow Worker
- Location – Since Dataflow use the cloud storage bucket to load the data into BigQuery, both BigQuery and GCS bucket should be in the same location. Otherwise we will get the error as “Cannot read and write in different locations”
Submit a BigQuery job using Cloud Dataflow
In this example, we are going to create a data pipeline for the below steps. Using Apache beam libraries, we are defining these steps in Python program.
- Read data from BigQuery
- Filter the records based on condition
- Write the filtered data into BigQuery
Step 1 : import libraries
First we need to import the beam and its PipelineOptions modules
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptionsStep 2 : Set arguments
Next we need to set the program arguments such as runner, job name, GCP project id, service account email, region, GCP temporary and staging location
pipeline_args=[
'--runner=DataflowRunner',
'--job_name=job-bq-to-bq',
'--project=my-rcs-project-833123',
'--service_account_email=svc-rc-bq-practice@my-rcs-project-833123.iam.gserviceaccount.com',
'--region=us-central1',
'--temp_location=gs://rc-beam-test/temp',
'--staging_location=gs://rc-beam-test/stage'
]Step 3 : Set pipeline options
By using the pipeline arguments, we need to set the beam PipelineOptions
pipeline_options = PipelineOptions (pipeline_args)Step 4 : Create Beam pipeline
In this step, we are creating the beam pipeline object with the Pipeline options.
pipeline = beam.Pipeline(options=pipeline_options)Step 5: Define the schema of BigQuery table
In order to write the output into BigQuery table, we are defining the schema of the table as below
table_schema = 'cust_id:INT64, category_code:STRING,subscribed_products:STRING,address:STRING,country:STRING'Step 6 : Read data from BigQuery table and Filter the records
Using beam pipeline object pipeline, we are defining our data pipeline steps such as read data from BigQuery and Filter out the records
bq_filter_rows = (pipeline
| "READ_BQ" >> beam.io.gcp.bigquery.ReadFromBigQuery(
query='SELECT * FROM `my-rcs-project-833123.rc_fin_test_tables.customer_360` limit 10', use_standard_sql=True)
| "FILTER_RECORDS" >> beam.Filter(lambda row: row['country'] == 'USA')
)Step 7 : Load/Write the data into BigQuery table
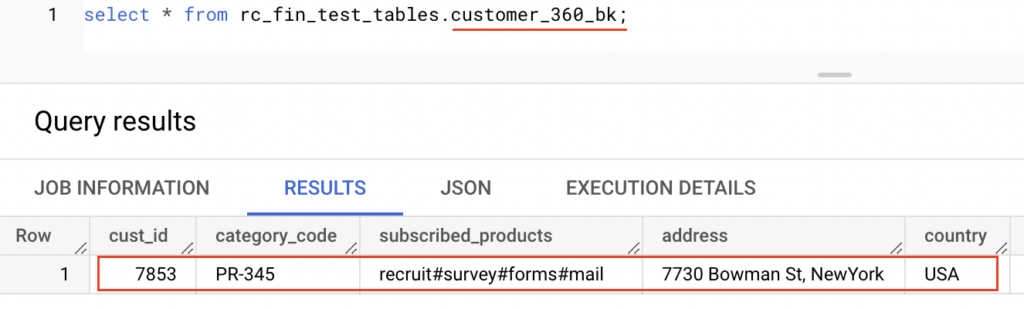
The PCollection object bq_filter_rows contains the filtered records. We are writing this object into another BigQuery table customer_360_bk.
data = (bq_filter_rows
|"WRITE_BQ" >> beam.io.gcp.bigquery.WriteToBigQuery(
project='my-rcs-project-833123',
dataset='rc_fin_test_tables',
table='customer_360_bk',
schema=table_schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED
))Step 8 : Run the beam Pipeline
Finally we can call the run method using pipeline object pipeline.
pipeline.run()Run the program
Let’s combine all the steps together and save the file as bq_pipeline.py. Since we are using Python version 3 in our machine, we are running this program using command python3
python3 bq_pipeline.pyOutput
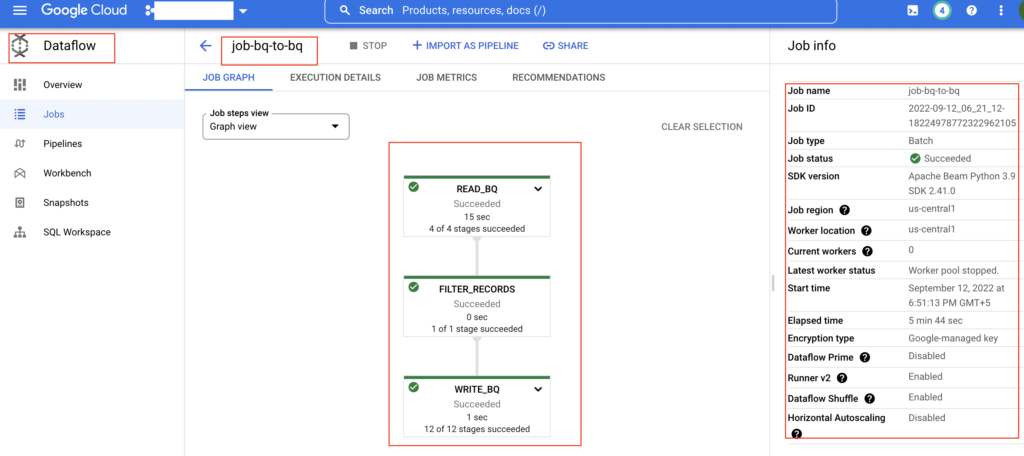
After executing the python program, the data pipeline is created in Cloud Dataflow. As shown below, the job name of the data pipeline is job-bq-to-bq. It contains three steps such as READ_BQ, FILTER_RECORDS and WRITE_BQ.
All three steps are executed successfully and it loaded the data into the target BigQuery table
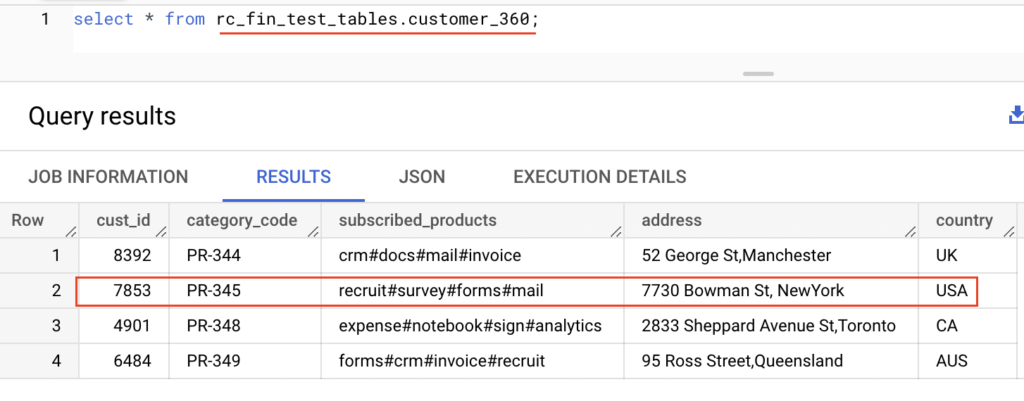
Source table : customer_360
Target table : customer_360_bk
Complete Python program to run a Beam pipeline in Dataflow : bq_pipeline.py
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
# set pipeline arguments => runner, gcp project details and gcs location
pipeline_args=[
'--runner=DataflowRunner',
'--job_name=job-bq-to-bq',
'--project=my-rcs-project-833123',
'--service_account_email=svc-rc-bq-practice@my-rcs-project-833123.iam.gserviceaccount.com',
'--region=us-central1',
'--temp_location=gs://rc-beam-test/temp',
'--staging_location=gs://rc-beam-test/stage'
]
# target table schema => column_name:BIGQUERY_TYPE, ...
table_schema = 'cust_id:INT64, category_code:STRING,subscribed_products:STRING,address:STRING,country:STRING'
# create PipelineOptions using pipeline arguments
pipeline_options = PipelineOptions (pipeline_args)
# create beam pipeline object
pipeline = beam.Pipeline(options=pipeline_options)
# Read from BigQuery and Filter out the records
bq_filter_rows = (pipeline
| "READ_BQ" >> beam.io.gcp.bigquery.ReadFromBigQuery(
query='SELECT * FROM `my-rcs-project-833123.rc_fin_test_tables.customer_360` limit 10', use_standard_sql=True)
| "FILTER_RECORDS" >> beam.Filter(lambda row: row['country'] == 'USA')
)
# Writing to BigQuery
data = (bq_filter_rows
|"WRITE_BQ" >> beam.io.gcp.bigquery.WriteToBigQuery(
project='my-rcs-project-833123',
dataset='rc_fin_test_tables',
table='customer_360_bk',
schema=table_schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED
))
# run beam pipeline
pipeline.run()Recommended Articles
- How to schedule and run BigQuery using Cloud Composer?
- How to read BigQuery table using PySpark?
- How to run BigQuery SQL using Jupyter notebooks in GCP?
References from GCP official documentation
- Installing the Apache Beam SDK
- Setting pipeline options
- Apache beam in GitHub
- Dataflow security and permissions
Your Suggestions